Build vs. Buy
👳🏽♂️
Ekam Singh / September 25, 2018
8 min read
An essential part of any software company is the tooling required to build, test, deploy, release, and monitor their software. This is an integral part of the software development life cycle (SDLC). Whether you should build or buy this tooling is a critical, expensive decision.
Can we find an off-the-shelf product that satisfies the needs of our company? What about an open-source solution? Do we need to build something custom? There are many factors that influence this decision. It ultimately depends on the nuances of your company, industry, and product.
This article will be a real-world example of why we chose to build our own monitoring and alerting system to support our Software as a Service (SaaS) product. To start, let me first explain the company and give some background.
What is Workiva?
Workiva (WK) is a cloud-based software company in the finance industry used by over 80% of Fortune 500 companies. Founded in 2008, we now have over 1200 employees and many offices around the world.
We want to ship quality code as fast and securely as possible. I joined Workiva in 2015 to work at the end of our DevOps pipeline: monitoring.
“DevOps is a set of practices intended to reduce the time between committing a change to a system and the change being placed into normal production, while ensuring high quality.”
State of Monitoring (2015)
An engineer on a product team is given requirements for a task to complete. After making the necessary code changes and testing her work, she opens a pull request (PR) on GitHub to have the changes reviewed by her team.
Static analysis (e.g. code linting) and test suites run against her code. If all checks pass and the PR has been properly reviewed, it is merged and the code will make its way to production.
Let’s say a user encounters an error while using our product. How does the engineer who created the new feature know that things are broken? Ideally, this error would trigger an alert to notify the engineer that there was a problem.
Unfortunately, this was not the reality for most engineers at this time. The main source of notification was via a daily email instead of near real-time alerting to a chat room. Theoretically, engineers could query the logs in Splunk at any time to find out if there was a problem. Unfortunately, many engineers found the query language difficult to understand.
This meant it sometimes took hours before engineers reacted to an issue if there hadn’t been a complaint from a customer yet. We wanted to improve our support process and ideally fix issues before customers even noticed there was a problem. We wanted every team to be set up with near real-time alerting for the errors they cared about. These alerts needed to be relevant and helpful, decreasing the time it took to analyze and fix issues.
Evaluating Options
Our company, product, and industry presented us with some difficult requirements:
- Strict security and compliance requirements
- Sensitive customer data
- A wide variety of programming languages (some not well used)
- Massive code base (100s of repositories) would require a lot of changes
Not a single off-the-shelf solution we found supported every major programming language we used. This wasn’t a complete showstopper, because some had REST APIs or other methods of getting data sent to their product. It just required a bit more work.
At the time, very few had SOC compliance or the ability to run on-premise. This was a deal breaker for a lot of the options we considered since the security of our customer’s data is paramount.
We evaluated the time it would take to adopt the final two contending solutions to match our infrastructure and processes. Did they have all the features we wanted? How much of our codebase would we need to modify to make their product work? Would we be guaranteed support from the company in case we encountered bugs or intricacies with their system? Would we be able to create integrations for company-specific needs?
Our Decision
After weighing the options and much debate, we decided it was in our best interest to build our own solution, utilizing existing Infrastructure as a Service (IaaS) solutions like Amazon Web Services (AWS) and Google App Engine (GAE) which allow you to only pay for what you need. Our main goals behind this decision were to:
- Provide value faster by incrementally building a new solution versus adapting to existing solutions
- Create a scalable, reliable platform that will revolutionize the support process of our products
- Drive the adoption of this solution by desire and not requirement so that 100% of production services have near real-time alerting set up
That’s where my journey with Workiva began as we started building our monitoring and alerting system.
How Does It Work?
This section dives into the technical details of how the system is built. If you’re just wondering what the outcome was, skip to the next section.
At the core of the system is the actual log message. To ensure all things are formatted and presented in the same way, we have a logging specification for each major language we use.
We have a layer of abstraction on top of each language that captures the language’s stdout and transforms it to follow the logging specification. These libraries also provide a platform for other information like telemetry, analytics, and tracing data.
The logs are then sent to Splunk as well as an AWS Kinesis stream. This stream allows us to process large amounts of data records in near real-time. Using AWS Lambda functions, we process and send the information to our GAE application for data storage.
The main reason we chose GAE over AWS for the rest of our application was so our support product was decoupled from our production product. It could have lived entirely in AWS if we were so inclined. Nonetheless, the information gets sent from Lambda to our GAE application created with Python and Flask.
The front-end of our web application was originally created with JavaScript & React, but we eventually ended up porting to Dart instead. This is due to the large investment in the Dart ecosystem our company has and the opportunity to dogfood our existing open-source software and tooling.
State of Monitoring (2018)
Over the past 3 years, we’ve worked tirelessly to create a product that revolutionizes the support process. It’s now a mature product with over 10,000 commits and 700 releases. Most importantly, we have achieved our goal of 100% of production services having near real-time alerting set up.
Let's walk through a typical use case of the product. First, a user will set up alerting rules so they are notified of the errors they care about. This could be a HipChat or Slack alert.

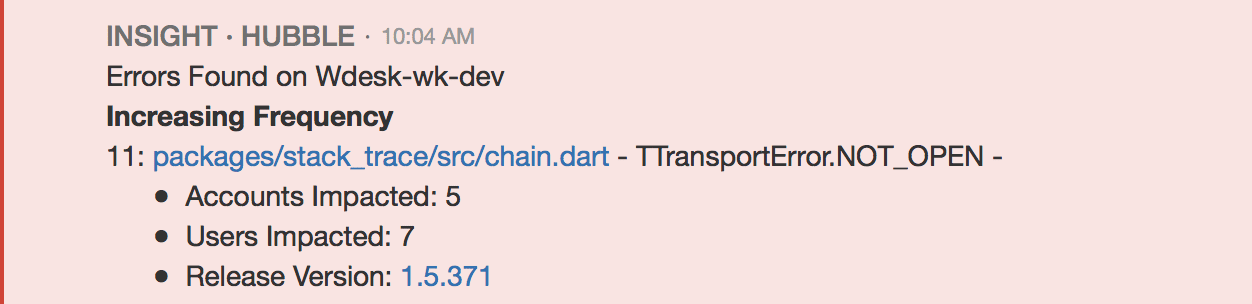

From here, the user is taken to our application to inspect the error.

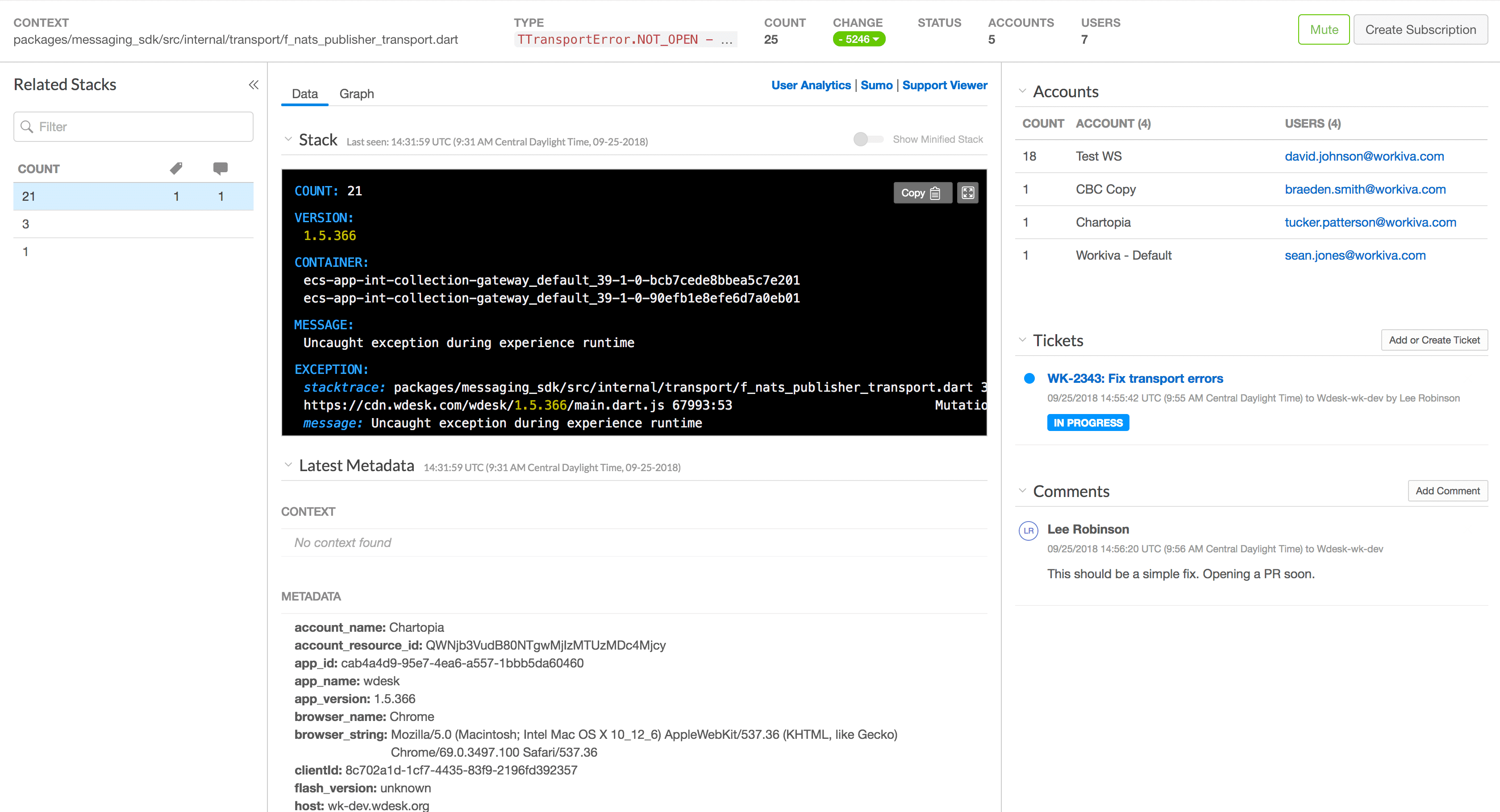
This is the complete overview of this specific error. You'll see similar stack traces, relevant metadata, accounts/users affected, comments, JIRA tickets, and more.

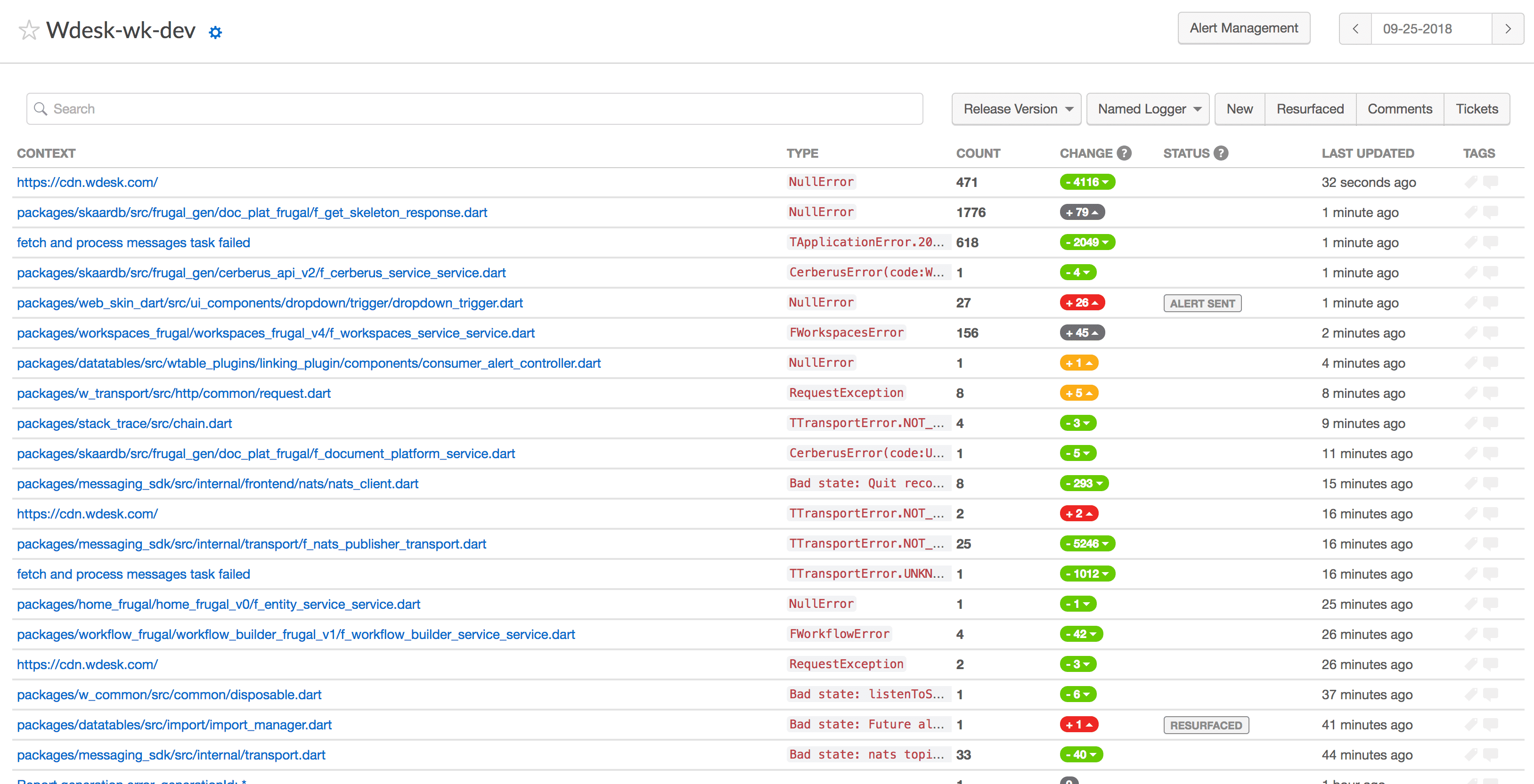
Errors are segmented by projects. There are different projects for each environment (e.g. dev, sandbox, prod). The above image shows the project overview listing all errors for the given day. Users have the ability to search and filter their results to find what's most important.
Teams are able to proactively fix issues before customers notice. We have processes in place to support the rollout of our next generation products. In almost all regards, this product was a success. However, has the rest of the industry caught up?
We periodically compare our application against other third-party and open-source solutions to see if we’re still providing more value (ideally at a lower cost). Most of the features we built over the past 3 years are now available in other solutions. The industry has caught up in most regards, as exception monitoring has become a necessity of supporting SaaS products.
Conclusion
As of right now, it is still cheaper for us to host our own solution versus migrating over to another provider. If hosting costs were to change, or the volume of logs was to drastically increase, this might not be true. This is why it’s important to constantly evaluate your product against others to determine when it’s right to build vs. buy. If your team currently doesn’t have any exception monitoring, we would recommend either Sentry or BugSnag.
Subscribe to the newsletter
Get emails from me about web development, tech, and early access to new articles.
- subscribers – 28 issues